
Nevrale Nett
Eit Nevralt Nett (NN) er ein veldig forenkla modell av eit biologisk nervesystem beståande av modell-nevroner som kommuniserer med kvarandre. Nokre av disse nevronene tar i mot input frå omverda og andre gir output, mens somme bare "snakkar" med andre nevroner. (Disse kallast på godt norsk for "hidden" - skjulte. Biologiske nett mottar impulsar frå feks. celler i auget, eller øyret, og sender ut signaler til musklar etc. I modellverda sender vi inn mønster beståande av tal, og får ut andre tal. Skjematisk kan vi framstilla et nevtalt nett slik:
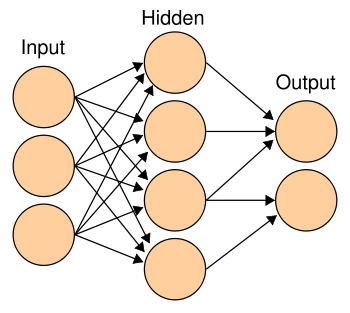
Dette er eit såkalt Feedforward-nett: eit nett som ikkje har tilbakekobling eller loopar. Alle koblingane frå input fører til det skjulte laget, og alle koblingar derfrå fører til output.
BIOLOGISK INSPIRERT:
Et verkelig nevron er ei spesialisert celle som er i stand til å motta signaler frå andre nevroner, "prosessera" denne informasjonen og senda ut signaler til andre celler basert på ei form for "utrekning". Enkelt sagt sender nevroner ut ein elektrisk puls når summen av innkommande signal overstig ein bestemt grenseverdi. Om nevronet skal "fyra av" ein puls avheng av kor mange av nabonevronene som fyrer av samtidig, kor sterke koblingane er mellom nevrone og kor høg grenseverdien er.
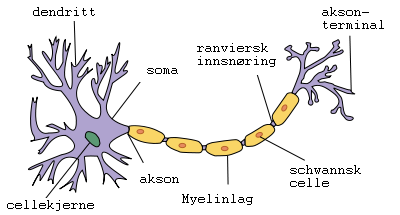
Biologiske nevroner kjem i mange ulike variantar, men er i prinsippet ganske enkle. Det er måten dei samarbeider på som gjer Nevrale Nett så komplekse. (sjå: hjernen) Avgjerande er korleis dei er knytta saman, og kor sterke koblingane (synapsane) er. Det første handlar om strukturen av nettet, det andre korleis nettet lærer. Eit biologisk nett vil utvikla seg gjennom heile levetida. Det oppstår stadig nye koblingar, mens andre forsvinn. Samtidig forandrar styrken på koblingane seg heile tida. Noko av dette er bestemt av arv, resten er tilpasning til omgivelsane.
MATEMATISKE MODELLAR:
For å etterlikna verkelege nett er det utvikla mange matematiske modellar. Ein veldig enkel modell av eit nevron er at utgangen er enten på eller av, representert ved 1 eller 0. For å avgjera om det er "på" så utfører det ein sk. vekta sum av input, og samanliknar svaret med ein grenseverdi.
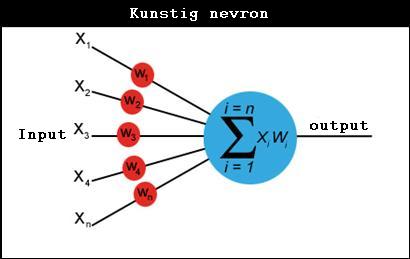
Anta at det får input frå tre nabonevroner og at to av dei er på (sender inn ein 1) Styrken på koblingane mellom disse er representer ved eit tall som vi kallar "vekt". Anta at w1 = 0.5, w2 = 0.3 0g w3 = -0.1. Vi merkjer oss at vekter kan vera negative. Det betyr at hvis nevron nr 3 er på, så hvil det hindra at mottakarnevronet vårt fyrer av, mens dei to andre vil stimulera det.
Vi får S = 1*0.5 + 0*0.3 + 1*(-0.1) = 0.4
Vil nevronet fyra? Ja, det avheng av grenseverdien det har. Hvis vi antar at grenseverdien g = 0.3 så vil det fyra fordi 0.4 > 0.3. (Men hvis vekt nr. hadde vore større, feks, 0.3, så hadde det ikkje gjort det likevel, for då ville den vekta summen ville blitt 0.2) Vi ser altså at vårt nevron vil "kjenna igjen" mønsteret 101, som vi har rekna ut, dvs. det vil fyra av hvis denne tallkombinasjonen dukkar opp. Dei vil også fyra av for nokon andre mønster, men ikkje for andre.
MØNSTERGJENKJENNELSE
Mønstergjenkjenning er ein vanlig anvendelse av nevrale nett. Poenget er at vi kan bestemma kva slags mønster nevronet vårt skal "kjenna igjen" og kva det skal ignorera, ved å endra vektene og grenseverdien. Dette kallast læring. Når vi bare har et nevron kan vi klara det ved prøving og feiling, men det skal ikkje så mange fleire til før det blir umulig. Heldigvis fins det sk. læringsalgoritmar, dvs. eit lite dataprogram som fikser dette.
Eit enkelt mønster på tre tall, er kanskje ikkje så interessant. Men når vi aukar antallet input og antallet nevronar så kan vi få et nett til å kjenna igjen ganske komplekse mønster. Hvis vi aukar til 64 input så kan vi la disse representera eit rutemønster på 8 x 8 ruter, og trena det opp til å kjenna igjen enkle bokstavliknande mønster.

Kanskje er dette fremdeles ikkje så veldig imponerande. Men ved å auka det endå meir kan nevrale nett brukast til ganske avansert bildegjenkjennings-oppgaver. Også talegjenkjenning kan vi trena eit nevralt nett til, ved å omdanna talesignalet til eit slags todimensjonalt bilde.
LÆRING OG GENERALISERING
Vi kan altså læra eit nett til å kjenna igjen bestemte mønster. Det gjer vi ved ein læringsalgoritme. Vi startar då ofte med tilfeldige vekter og presenter nettet for eit mønster om gangen og justera vektene litt etter litt til vi får det svaret som vi ynskjer. Og hvis vi har vore flinke så gir ikkje bare nettet riktig svar på mønster som det er trent opp med, men også på mønster som liknar. Hvis vi har trent det på ein "A" så vil vi gjerne at det skal kjenna igjen ein "A" også. Vi seier då at nettet vårt generaliserer bra, og det er ein viktig egenskap for nevrale nett. For då kan eit nett også klara å kjenne igjen mønster med støy, feks utydelige bilder.
Men det er ikkje alltid det er mulig å trena opp eit nett til det du hadde tenkt. Av og til lærer ikkje nettet det de skal. Det kan vera at mønsteret er for komplekst, og då kan det hjelpa å auka antallet nevroner dvs. nettets egen kompleksitet. Andre gonger lærer nettet veldig bra på treningseksempela, men generaliserer dårlig. Det er ikkje i stand til å kjenne igjen ein sjølv mønster som er veldig like på det vi har trent det opp på, og løysinga kan då faktisk vera å redusera antallet nevroner.
Konklusjonen er at det ikkje bare er korleis nettet lærer, men også strukturen (antallet nevroner og korleis dei er kobla saman) som betyr noko for nettets prestasjonar. Dette kan du lesa om i "Optimalisering av nettverkstopologi". Men først er det kanskje lurast å lesa om Genetiske Algoritmer.